
Förändringsbar arkitektur
Det här är del 3 i en serie artiklar om hur Archify ser på
IT-arkitektur. Med värderingar och reflektioner om hur vi bygger bra IT-system.
IT-arkitektur som följer verksamheten
När vi utvecklar IT-system vill vi undvika att behöva bygga nytt med jämna mellanrum. Vi vill uppnå en livscykel som är mer evolutionär i sin karaktär (se Archify artikel del 2). Då gäller det att vi kan hantera förändringar på ett bra sätt.
Jag tror man ska undvika att ta fram en IT-arkitektur som återspeglar den aktuella organisationen. Tänk efter hur ofta det sker organisationsförändringar i ditt företag. Det gäller att ta hänsyn och frikoppla sig från Conways lag (se Archiy artikel del 1).
Istället bör man fokusera och styra sin IT-arkitektur till att återspegla de förmågor som finns i verksamheten. Förmågor kan förändras i sitt utförande, men överges eller tillkommer relativt sällan. Föreställ dig ett handelsföretag som har förmågan att ”sälja varor”. Det är en kärnförmåga som antagligen är beständig över tid, ”sälja varor”. Däremot kan handelsföretaget förändra hur den säljer varor. Kanske vill man börja sälja via nya kanaler, t ex e-handel. Handelsföretaget kan också ha förmågor som att ”ta betalt”, ”lagerhålla varor”, ”leverera varor”, ”kundpolicys med belöningssystem”, osv.
När vi pratar förmågor ser vi enbart till hur verksamheten fungerar. Vad den gör. Vi tar alltså inte utgångspunkt från teknisk lösning och IT här.
Orsaker till förändring
Vi har tidigare i artikel 1 och 2 pratat om orsaker till förändring. Då tänker jag på förändring som påverkar vårt IT-system och kanske vår IT-arkitektur. Som nämns ovan kan det vara organisationsförändringar. Verksamhetsmässiga förändringar kan hända relativt ofta, även om hela förmågor sällan försvinner eller tillkommer. Nya regelverk och lagar ställer nya krav och ger nytt behov av IT-stöd. Effektiviseringskrav och kostnadsbesparingar kan driva förändringar. Ny teknik kan ge effektivisering och kostnadsbesparing på sikt, eller ge andra fördelar i form av prestanda och skalbarhet.
Fallgropar med Microservices
Det är idag populärt att bryta upp system i mindre beståndsdelar. Microservices har varit en stark trend de senaste åren med influenser från framåtriktade företag som Netflix, Uber, Amazon, Twitter, mfl. Det gör ju att många ”vanliga” företag naturligtvis också vill ta efter. Men det är många fallgropar i den typen av arkitektur. Många arkitekter och utvecklare kommer från monolitiska applikationer och vill börja bryta upp sitt system. Det är en hög tröskel där jag anser att det ofta saknas erfarenhet och rätt ansats för att lyckas. Det behövs ett stort lärande. Det gäller att använda rätt mönster på rätt ställe för att undvika alla fallgropar som följer med Microservices.
Det kan vara läge att nämna några av de fallgropar jag pratar om. Några fallgropar handlar direkt om följden av distribution. Vi som jobbat med distribuerade system känner antagligen till t ex fallgroparna med distribuerade system (i.e. the fallacies of distributed computing)[1]. Sedan har vi problematiken som har att göra med konsistens (eventual consisistency), transaktionshantering, felhantering, felkaskadering, kompensation, samtidighet (race conditions), ordningsföljd, tillgänglighet/återförsök, prestanda. Alla har stor betydelse i ett distribuerat system. Många av de svårigheter jag nämner är av teknisk karaktär. För att hantera det tekniska finns det framtagna lösningsmönster inom mikrotjänste-världen, såsom circuit breaker och bulkhead, som parerar vissa av problemen. Det som jag ändå anser vara den mest avgörande fallgropen med mikrotjänster är hur vi definierar tjänsterna, dvs hur man delar upp logik och data i autonoma tjänster. Detta grundar sig i att vi bättre behöver förstå verksamheten. Det kan göra att vi till och med slipper få några av de tekniska utmaningar jag nämnde. Det handlar om att skapa tjänster med hög sammanhållning (cohesion) och låg koppling (coupling).
Objektorienterade IT-tjänster
Många som arbetat med systemutveckling känner till principer om objektorientering (OOA/OOD) och flerskiktade lösningar (presentation/logik/data). Tyvärr har det en tendens att smitta av sig på hur man väljer att skapa sina mikrotjänster. Man väljer att skapa mikrotjänster utifrån substantiv, objekt. T ex order, faktura, produkt, kund, användare. Något som tangerar det här är att man väljer att skapa datadrivna tjänster. Man tar en tabell i datamodellen och gör den till en mikrotjänst (väldigt förenklat uttryckt såklart). Återigen, tabeller benämns ofta med substantiv. Men vad är egentligen problemet med det här?
Det första jag tänker på är att logik sällan är isolerad till ett objekt. Det innebär att:
- Samma, eller relaterad, logik måste finnas i flera tjänster
- En tjänst har beroende till andra tjänster
Det ger varken hög sammanhållning eller låg koppling. Tvärtom. Det strider även mot Single Responsiblity Principle, dvs att varje ”modul” enbart ansvarar för en sak och kapslar in det ansvaret, alltså att det inte är utspritt över fler moduler.
I en monolitisk arkitektur ser man oftast korsberoenden mellan lagrens olika objekt. Se figur 1.
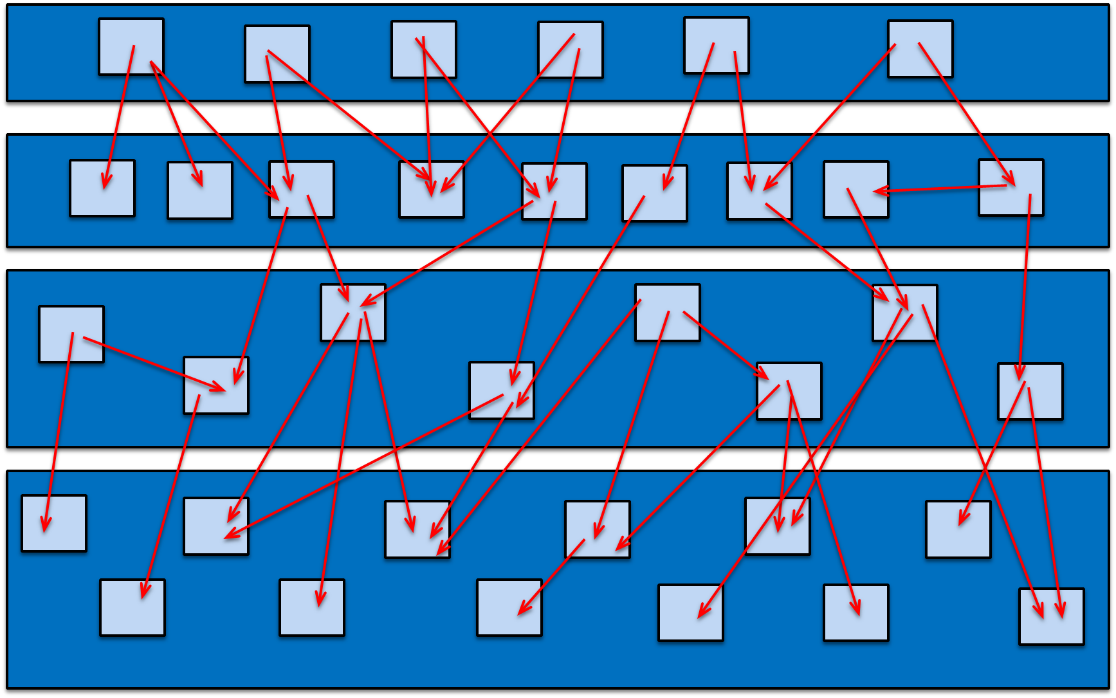
Figur 1. Korsberoenden mellan lagrens olika objekt
Tanken här är ju att lagret ovanför använder objekt från lagret direkt nedanför. Jag tänker lite såhär:

Figur 2. Antal (objekt) och omfång (”funktionalitet”) i en klassisk flerskiktad arkitektur
Antalet objekt ökar ju längre ner man kommer i lagren. Det är t ex flest dataentiteter, något färre logikobjekt, ännu färre tjänster i eventuellt servicelager. Omfånget i både antal objekt och i funktionalitet ökar ju högre upp man kommer i lagren. Man kan tänka sig att GUI är ett objekt, och det kan ibland bara finnas ett GUI som hanterar all funktionalitet och alla objekt, i nån form av komposition. Man kan tänka också tänka sig omfång och antal i form av utgående pilar. Se figur 2.
Många tar sina objekt, t ex kund, och plockar ihop allt som har med kund att göra och skapar en mikrotjänst som heter CustomerService. Det gör det naturligt att allt som har med Kund att göra samlas i den tjänsten.

Men har vi hög sammanhållning i den här tjänsten? Brukar adress avgöra om en kund får högre kredit (Change_Credit) eller kan bli priviligierad som kund (Make_Preferred)? Vi får en tjänst som blir stor i sitt omfång. Risken är också att vi får andra tjänster som behöver information som finns här för att fullgöra sin förmåga. Exempel. Om kunden ska lägga en order, så bör vi ha en OrderService som hanterar det. Innan ordern läggs kan vi behöva vi ta reda på om kunden har kredit, och då måste OrderService anropa CustomerService. Om vi ska skicka en order, som hanteras av ShippingService, måste vi fråga CustomerService efter adressen. Om vi ska ta betalt, som hanteras av BillingService, måste vi fråga vilken kredit kunden har. Det som blir påtagligt här är att man måste vara nog med var datan hör hemma, och då måste man vara nog med frågorna kring datan. Exempelvis kring adress. vi behöver ställa mer frågor om när och var adress används i verksamheten. Adress kan användas som leveransadress när vi ska skicka varor. Eller adress kan användas för fakturering för att skicka fakturor. Eller adress kan vara en besöksadress för våra kundbesök. Adress är alltså egentligen 3 olika begrepp/objekt som skulle hypotetiskt kunna höra hemma i ShippingService, BillingService respektive CustomerCareService. Det här att vi skapar tjänster utifrån objekt/substantiv innebär att vi får hög koppling mellan våra definierade tjänster. Vi skulle kunna hantera det genom att dela databas, eller skapa dataobjekt som blir en mikrotjänst. Då kan vi ju återanvända dataobjekt mellan tjänster. Det här leder till, alltså om man skapar mikrotjänster baserat på objekt och för att stödja återanvändbarhet utifrån objektorienterade principer, till en ny monolit. Låg sammansättning, hög koppling. Det brukar kallas för big ball of mud, vilket är en variant av det vi på svenska kallar ”spagettikod”. Så vår flerskiktade objektorienterade monolit har blivit en mikrotjänste-arkitektur som ärver samma negativa egenskaper. ”Bilden” blir densamma om man ser på våra hårda beroenden. Här är bara varje låda en mikrotjänst istället för ett objekt.

Figur 3. Korsberoenden mellan microservices
IT-tjänster som följer verksamhetens förmågor
Vi måste hitta verksamhetens förmågor istället! Och skapa tjänster som skär isär logik och data på tvären. Ungefär så som beskrivs i figur 4.

Figur 4. SOA/Micro-tjänster "the Archify Way"
En tjänsts gräns innefattar allt från användargränssnitt till lagring av sitt data. Det här bör ses som en logisk struktur. Ibland kan en tjänst vara utspridd och t ex innefatta både egenutvecklade webtjänster och funktioner som realiserats i ett standardsystem. Men den logiska tjänsten ger möjlighet att svara på vem som är auktoritet för en given förmåga. Det ger möjlighet att ha tydliga kontrakt mot omvärlden. Det innebär också att vi kan sätta principer kring vad som är tillåtet inom en tjänst och mellan tjänster, för att på sätt upprätthålla självständighet och sammanhållning inom en tjänst och även en låg koppling mellan tjänster.
Att definiera de här tjänsterna, dvs att hitta de här förmågorna och gränserna för varje tjänst är en stor utmaning. Det kräver ett stort tålamod och ett djupt samspel mellan IT och verksamhet. Något som sällan mäktas med i tidspressade projekt, tyvärr. Jag är dock övertygad om att den tiden tjänas in mångfaldigt på sikt, och kommer ge en mer framgångsrik IT-arkitektur som klarar förändring och kan möta framtidens nya krav och behov.
I nästa del kommer vi se hur en sådan här tjänstearkitektur kan glänsa i olika scenarios. Det första scenariot jag tänkte beskriva är standardsystem. På återhörande.
[1] https://en.wikipedia.org/wiki/Fallacies_of_distributed_computing, mer beskrivet: https://www.simpleorientedarchitecture.com/8-fallacies-of-distributed-systems/